这个帖子会讲解一个U-Net训练时载入图像的案例。程序是由Cursor中Claude 3.7所写,有些过分专业,这里附上解释,作为U-Net教学实操的第一部分。
本教案数据来自Kaggle: DRIVE Digital Retinal Images for Vessel Extraction | Kaggle
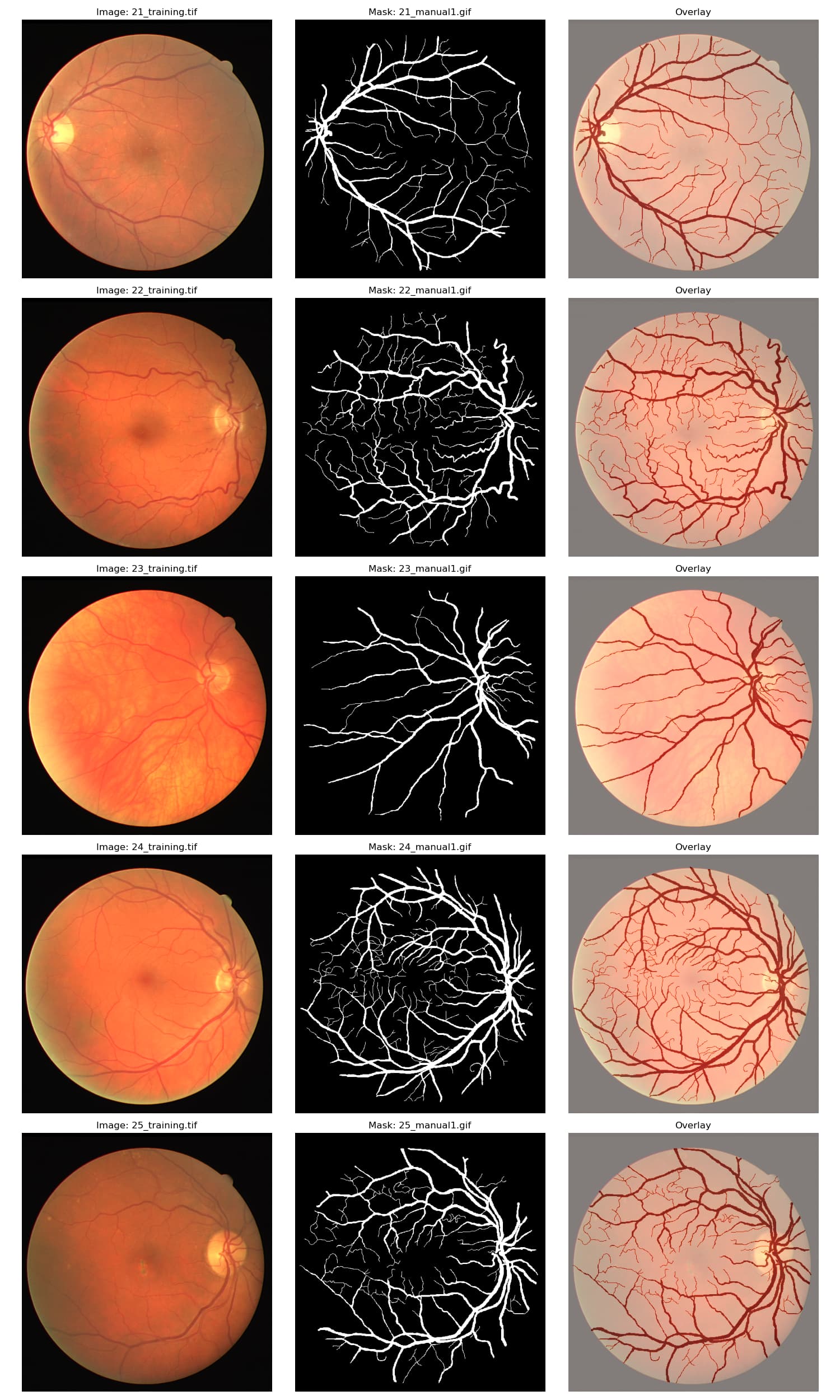
首先看一下文件夹和图片的格式:
/d:/ia4u/courses/从0开始训练你的AI分割模型/课程/U-Net/Retina/
├── training/
│ ├── images/ # Contains training images
│ │ ├── image1.tif
│ │ ├── image2.tif
│ │ └── ... # Other training images
│ └── masks/ # Contains corresponding masks for training images
│ ├── mask1.gif
│ ├── mask2.gif
│ └── ... # Other training masks
└── test/
├── images/ # Contains testing images
│ ├── test_image1.tif
│ ├── test_image2.tif
│ └── ... # Other testing images
数据载入整体代码如下:
import os
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import glob
from torchvision import transforms
class RetinaDataset(Dataset):
def __init__(self, img_dir, mask_dir=None, transform=None, is_test=False):
"""
Args:
img_dir (string): Directory with all the images.
mask_dir (string, optional): Directory with all the masks.
transform (callable, optional): Optional transform to be applied on a sample.
is_test (bool): Whether this is a test dataset (no masks)
"""
self.img_dir = img_dir
self.mask_dir = mask_dir
self.transform = transform
self.is_test = is_test
# Get all image paths
self.img_paths = sorted(glob.glob(os.path.join(img_dir, '*.tif')))
# Get corresponding mask paths if not test set
if not is_test and mask_dir is not None:
self.mask_paths = []
for img_path in self.img_paths:
img_name = os.path.basename(img_path).split('_')[0]
mask_path = os.path.join(mask_dir, f"{img_name}_manual1.gif")
if os.path.exists(mask_path):
self.mask_paths.append(mask_path)
else:
print(f"Warning: No mask found for {img_path}")
# Ensure we have the same number of images and masks
assert len(self.img_paths) == len(self.mask_paths), "Number of images and masks don't match"
def __len__(self):
return len(self.img_paths)
def __getitem__(self, idx):
# Load image
img_path = self.img_paths[idx]
image = Image.open(img_path).convert('L') # Convert to grayscale
# Convert to numpy array
image = np.array(image)
# Normalize image to [0, 1]
image = image / 255.0
if self.is_test:
# For test set, only return the image
if self.transform:
image = self.transform(image)
# Convert to tensor if not already
if not isinstance(image, torch.Tensor):
image = torch.from_numpy(image).float() # Explicitly use float32
# Add channel dimension if needed
if len(image.shape) == 2:
image = image.unsqueeze(0)
return {'image': image, 'filename': os.path.basename(img_path)}
else:
# Load mask for training set
mask_path = self.mask_paths[idx]
mask = Image.open(mask_path).convert('L') # Convert to grayscale
mask = np.array(mask)
# Binarize mask (0 or 1)
mask = (mask > 0).astype(np.float32) # Explicitly use float32
# Apply transformations if specified
if self.transform:
# Apply same transform to image and mask
sample = self.transform({'image': image, 'mask': mask})
image, mask = sample['image'], sample['mask']
# Convert to tensor if not already
if not isinstance(image, torch.Tensor):
image = torch.from_numpy(image).float() # Explicitly use float32
mask = torch.from_numpy(mask).float() # Explicitly use float32
# Add channel dimension if needed
if len(image.shape) == 2:
image = image.unsqueeze(0)
if len(mask.shape) == 2:
mask = mask.unsqueeze(0)
return {'image': image, 'mask': mask, 'filename': os.path.basename(img_path)}
class DualCompose:
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, sample):
for t in self.transforms:
sample = t(sample)
return sample
class RandomHorizontalFlip:
def __init__(self, p=0.5):
self.p = p
def __call__(self, sample):
if np.random.random() < self.p:
sample['image'] = np.fliplr(sample['image'])
sample['mask'] = np.fliplr(sample['mask'])
return sample
class RandomVerticalFlip:
def __init__(self, p=0.5):
self.p = p
def __call__(self, sample):
if np.random.random() < self.p:
sample['image'] = np.flipud(sample['image'])
sample['mask'] = np.flipud(sample['mask'])
return sample
class ToTensor:
def __call__(self, sample):
image, mask = sample['image'], sample['mask']
# Convert numpy arrays to tensors
image = torch.from_numpy(image).float() # Explicitly use float32
mask = torch.from_numpy(mask).float() # Explicitly use float32
return {'image': image, 'mask': mask}
def get_train_transform():
return DualCompose([
RandomHorizontalFlip(),
RandomVerticalFlip(),
ToTensor()
])
def get_validation_transform():
return DualCompose([
ToTensor()
])
def get_test_transform():
class ToFloat32Tensor:
def __call__(self, pic):
# Convert PIL Image or numpy.ndarray to tensor and ensure it's float32
if isinstance(pic, np.ndarray):
return torch.from_numpy(pic).float()
else:
return transforms.functional.to_tensor(pic).float()
return transforms.Compose([
ToFloat32Tensor()
])
下面将详细解释这段代码的每个部分,它主要包含了一个自定义数据集类 RetinaDataset 以及一些图像和 mask 数据的预处理(数据增强)操作。代码主要用于医学影像(这里是视网膜图像)分割任务。以下是对代码的逐行详细解释:
1. 导入所需的库
import os
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import glob
from torchvision import transforms
- os:用于操作文件路径和文件系统。
- numpy:进行数值计算和数组操作。
- torch 以及 torch.utils.data:PyTorch库及其数据加载模块,用于构建数据集和批量加载。
- PIL.Image:加载并处理图片。
- glob:方便地查找匹配特定规则的文件。
- torchvision.transforms:图像转换工具,用于数据预处理。
2. 自定义数据集类 RetinaDataset
此数据集继承自 torch.utils.data.Dataset,主要用来加载视网膜图像及其相应的 mask(在分割任务中 mask 用于标记前景区域)。
class RetinaDataset(Dataset):
def __init__(self, img_dir, mask_dir=None, transform=None, is_test=False):
"""
Args:
img_dir (string): 存储所有图像的文件夹路径。
mask_dir (string, optional): 存储所有mask的文件夹路径。如果是测试集可以不提供。
transform (callable, optional): 用于对样本进行预处理/数据增强的转换函数。
is_test (bool): 是否为测试数据集(测试集没有mask)。
"""
self.img_dir = img_dir
self.mask_dir = mask_dir
self.transform = transform
self.is_test = is_test
# 获取所有包含.tif后缀图像的路径,并按字母顺序排列。
self.img_paths = sorted(glob.glob(os.path.join(img_dir, '*.tif')))
# 如果不是测试集并且提供了mask目录,则加载对应的mask路径
if not is_test and mask_dir is not None:
self.mask_paths = []
for img_path in self.img_paths:
# 这里假设文件名以“_”分割,第一个部分作为名字
img_name = os.path.basename(img_path).split('_')[0]
# mask文件的命名规则:文件名后接"_manual1.gif"
mask_path = os.path.join(mask_dir, f"{img_name}_manual1.gif")
if os.path.exists(mask_path):
self.mask_paths.append(mask_path)
else:
print(f"Warning: No mask found for {img_path}")
# 确保图像和mask数量一致,不一致则报错
assert len(self.img_paths) == len(self.mask_paths), "Number of images and masks don't match"
说明:
- 构造函数
__init__:- 传入参数为图像目录、mask目录(可能为空)、transform转换以及是否为测试集(测试集只有图像,没有mask)。
- 使用
glob.glob搜索图像目录中所有的.tif图像,并按顺序排列。 - 如果是训练或验证数据集(
is_test=False)并且提供了mask_dir,那么根据一定的文件命名规则,为每张图像在mask目录中找到对应的mask文件。如果找不到mask,会打印警告信息;同时用assert语句确保图像和mask是一一对应的。
数据集的其他方法
__len__ 方法
def __len__(self):
return len(self.img_paths)
- 返回数据集中图像的数量,便于 PyTorch DataLoader 获取数据长度。
__getitem__ 方法
def __getitem__(self, idx):
# 加载图像
img_path = self.img_paths[idx]
image = Image.open(img_path).convert('L') # 将图像转换为灰度图('L'模式)
# 将PIL图像转成numpy数组
image = np.array(image)
# 归一化处理,将像素值缩放到[0, 1]
image = image / 255.0
- 根据索引
idx获取图像路径。 - 使用 PIL 打开图像,并转换为灰度模式('L’表示8位灰度图)。
- 将图像转换为 numpy 数组,并对像素值归一化。
接下来根据是否为测试集分别处理:
测试集部分 (is_test=True)
if self.is_test:
# 如果设置了transform,则应用该变换
if self.transform:
image = self.transform(image)
# 如果转换后结果不是Tensor,则转换为Tensor
if not isinstance(image, torch.Tensor):
image = torch.from_numpy(image).float() # 显式转换为float32
# 如果图像只有二维(没有channel维),则增加一个channel维度
if len(image.shape) == 2:
image = image.unsqueeze(0)
return {'image': image, 'filename': os.path.basename(img_path)}
- 对于测试集,我们只返回图像和文件名,不涉及 mask。
- 如果传入了 transform 就先执行 transform 操作。
- 检查转换结果是否为
torch.Tensor,如果不是则将 numpy 数组转换成 Tensor,并转换为float32。 - 如果图像是二维数据(形状例如
[H, W]),则用unsqueeze(0)在最前面增加一个通道维度(变成[1, H, W])。 - 返回一个包含图像和文件名的字典。
训练/验证集部分(即非测试集)
else:
# 加载对应的mask,过程同上,将mask也转换为灰度图
mask_path = self.mask_paths[idx]
mask = Image.open(mask_path).convert('L')
mask = np.array(mask)
# 二值化mask,即将mask中大于0的值设为1,小于等于0的设为0,并转换成float32
mask = (mask > 0).astype(np.float32)
# 如果有transform,应用于图像和mask。注意这里的transform需要同时处理image和mask
if self.transform:
sample = self.transform({'image': image, 'mask': mask})
image, mask = sample['image'], sample['mask']
# 如果转换结果不是Tensor,则转换为Tensor
if not isinstance(image, torch.Tensor):
image = torch.from_numpy(image).float() # 显式转换为float32
mask = torch.from_numpy(mask).float() # 显式转换为float32
# 如果图像或mask只有二维,则添加channel维度
if len(image.shape) == 2:
image = image.unsqueeze(0)
if len(mask.shape) == 2:
mask = mask.unsqueeze(0)
return {'image': image, 'mask': mask, 'filename': os.path.basename(img_path)}
- 加载 mask,同样转换为灰度图和 numpy 数组。
- 对 mask 进行了 二值化,即大于0的值变为1,确保 mask 中只有 0 和 1。
- 如果有提供 transform,则将图像和 mask 封装为字典传入 transform 操作(注意此时 transform 是为数据增强设计的,需要同时处理图像和 mask)。
- 同样保证转换结果为 Tensor,并添加 channel 维度以符合网络模型输入格式。
- 返回一个包含图像、mask和文件名的字典。
3. 数据增强和转换相关的类
下面几个类主要用于数据增强以及转换,它们实现了对图像和 mask 的预处理操作。
DualCompose 类
class DualCompose:
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, sample):
for t in self.transforms:
sample = t(sample)
return sample
- DualCompose:用于将一系列的转换(transform)组成一个组合(类似于
torchvision.transforms.Compose),但这里的转换针对的是同时包含图像和 mask 的字典。 - 在
__call__方法中,会依次对 sample 应用内部的每个转换。
RandomHorizontalFlip 类
class RandomHorizontalFlip:
def __init__(self, p=0.5):
self.p = p
def __call__(self, sample):
if np.random.random() < self.p:
sample['image'] = np.fliplr(sample['image'])
sample['mask'] = np.fliplr(sample['mask'])
return sample
- RandomHorizontalFlip:根据给定的概率
p随机将图像和 mask 进行水平翻转。 - 使用
np.fliplr实现水平翻转。
RandomVerticalFlip 类
class RandomVerticalFlip:
def __init__(self, p=0.5):
self.p = p
def __call__(self, sample):
if np.random.random() < self.p:
sample['image'] = np.flipud(sample['image'])
sample['mask'] = np.flipud(sample['mask'])
return sample
- RandomVerticalFlip:类似水平翻转,不过使用
np.flipud实现垂直翻转。
ToTensor 类
class ToTensor:
def __call__(self, sample):
image, mask = sample['image'], sample['mask']
# 将numpy数组转换为Tensor,并保证数据类型为float32
image = torch.from_numpy(image).float()
mask = torch.from_numpy(mask).float()
return {'image': image, 'mask': mask}
- ToTensor:用于将图像和 mask 从 numpy 数组转换为 PyTorch 的 Tensor,并转换数据类型为
float32。
在这个案例中,随机变换(例如 RandomHorizontalFlip 和 RandomVerticalFlip)在训练过程中只是在每次数据加载时对图像和对应的 mask 进行实时增强,而并没有在磁盘上生成新的图像文件,也没有真正增加训练集的样本数量。具体说明如下:
实时数据增强
当调用 __getitem__ 方法从数据集中读取一个样本时,会根据预设的随机概率对图像和 mask 执行翻转操作。每次获取的图像可能经过不同的翻转变换,这使得在训练过程中模型每次看到的图像可能其实是经过不同随机增强后的版本。
不改变原始数据集大小
实际存储在硬盘上的图像文件保持不变,并没有通过这些随机变换增加额外的数据样本,仅仅是在内存中动态生成了新的样本表示。
提高模型泛化能力
这种实时数据增强方法使得相同的原始图像可以在不同训练迭代中呈现出多样化的形式,从而提高模型对不同数据变换的适应性和泛化能力。
因此,在这个案例中,随机变换只是对原图进行实时变化(数据增强),并没有实际增加训练集的数量。
4. 获取各个阶段的转换函数
这些函数返回不同的转换组合,通常用于训练、验证和测试数据的不同预处理策略。
训练时的转换函数
def get_train_transform():
return DualCompose([
RandomHorizontalFlip(),
RandomVerticalFlip(),
ToTensor()
])
- get_train_transform 返回一个包含数据增强(随机水平和垂直翻转)以及转换为 Tensor 的组合。
- 训练过程中通过数据增强可以提高模型的鲁棒性。
验证时的转换函数
def get_validation_transform():
return DualCompose([
ToTensor()
])
- get_validation_transform 只进行转换为 Tensor,不做数据增强,以确保验证数据保持原始状态。
测试时的转换函数
def get_test_transform():
class ToFloat32Tensor:
def __call__(self, pic):
# 将PIL Image或numpy.ndarray转换为Tensor,并保证类型为float32
if isinstance(pic, np.ndarray):
return torch.from_numpy(pic).float()
else:
return transforms.functional.to_tensor(pic).float()
return transforms.Compose([
ToFloat32Tensor()
])
- get_test_transform 返回一个
torchvision.transforms.Compose的转换:- 内部定义了一个
ToFloat32Tensor类,它能够处理输入是 numpy 数组或 PIL Image,转换为 Tensor,并确保数据类型为float32。
- 内部定义了一个
- 测试集只需要转换成 Tensor,不需要数据增强,因此使用
transforms.Compose而非DualCompose(因为测试样本直接是图像而不是包含 mask 的字典)。
总结
-
数据集加载:
- RetinaDataset 类根据输入的图像目录和(可选的)mask目录加载数据,对于训练/验证集,确保图像和 mask 一一对应,并进行归一化、二值化处理,最后转换为 Tensor 格式;对于测试集,只加载图像并返回文件名。
-
数据预处理与增强:
- 定义了针对图像和 mask 的数据增强操作,如随机水平和垂直翻转。
- 定义转换操作
ToTensor保证输入转换为torch.Tensor。 - 通过
DualCompose将多个转换组合起来应用于包含 image 和 mask 的字典。 - 分别为训练、验证和测试阶段定义不同的转换函数。
以上代码实现了一个常见的医学图像分割数据集加载和预处理流程,可以直接用于搭建 PyTorch 分割训练的 DataLoader,从而方便后续模型的训练与验证。